| Main Page -> Papers -> On Systems Documentation |
On Systems Documentation
Introduction
Overview
Years of advocacy for effective documentation methods and the frustration at the results has brought me to a few conclusions about how to produce the best systems documentation. Here I am presenting my case in the discussion that all too many IT shops need to have with themselves about the value of their efforts in this area.
It is my understanding that we can't all be the Hemingway of technical writing. While good writing skills are necessary, they are not in themselves sufficient for successful documentation. Some approaches to documentation are destined to fail not for lack of effort, but for lack of focus on key details that will undermine the endeavor.
It is my contention that many of the token documentation efforts I have encountered are so conter-productive that people are better off not documenting at all. If you are burning man hours on ineffective and even misleading documentation, and no one in your group is rushing to help, then hopefully this paper will relate why.
So what are we talking about?
Setting some paramaters
First, let me define what I call "good" documentation. Good documentation is:
| • | an accurate representation of design and intent, |
| • | well written, |
| • | speaks to multiple technical levels, |
| • | and directly contributes to efficiencies in system management and future system design. |
Also, the core of this discussion is derived from a background in Unix, but relates to other systems such as Windows and even other disciplines such as storage and networking. If you are coming from another area, and some concepts seem a bit Unix-centric then translate as appropriate. I think the reader will find that most concepts and recommendations expressed here are entirely independent of the platform or technology documented. That said, most development / end-user / application documentation will be of a slightly different nature with less that is directly applicable. But ultimately, if you are documenting rocket ships, brain surgery, or how to make a good cup of coffee, the same principles of good writing and expression still apply.
Broken and Busted
Where Documentation systems have gone wrong
I have had the fortunate opportunity to visit and even work in numerous Unix shops. This exposure has allowed me to witness the effectiveness of many different approaches to capturing collective IT knowledge. This section consists of some of the more popular, yet least effective methods of systems documentation.
A top down approach to chaos management
Managers who value crisis people over proactive people are perpetuating their own pain.
The two ends of the IT worker spectrum are the employee of the year and the loafer.
The employee of the year is noted for his tireless devotion to solving every fire that erupts in his department. The employee of the year is always there in the midst of chaos pulling off the miraculous effort that, once again, saves the day and allows the companies core business to continue. Virtually everyone gets to meet and know this guy.
The loafer is frequently found chatting away with members of other departments, off in a corner writing some code, sitting around reading industry magazines, or passively watching some system. When asked, most people outside his group will not recognize him.
It is not hard to imagine these "end of the spectrum" employees, because they actually exist. We have seen them on the job and we have seen their results.
For those not in on the story, let me say that I emphatically endorse the loafer model. He is the proactive side of the scale that anticipates failure points in the system, designs for robustness, constantly monitors the health of the environment and has meaningful documentation. He uses his spare time to improve all of the above as well as working closely with other groups to see what IT can do to solve their problems.
The employee of the year does not have time to be proactive, to design effectively, or to develop meaningful documentation. He spends his time in the now with less thought of where he is going. He does not monitor systems, he monitors crises. When IT employees win the popularity contest called "Employee of the Quarter" it frequently means that they are spending too much time on the highly visible / wrong side of their systems.
The culmination of the non-believers
A documentation system falls apart when a significant portion of the group refuses to participate. It falls apart even faster when an individual updates a system and neglects highly synchronized / fragile documentation used to track it.
IT departments can survive occasional non-participation from members for most kinds of system documentation just like they do the occasional administrator introduced error. But when large portions of non-believers cease participation, it becomes exceptionally difficult for the remaining believers to keep a working documentation set.
Project & department managers need to set expectations for systems documentation. This begins with the recognition that the information has a tangible, monetary, value to the organization. When this information is allowed to slip away then it must be recreated each time those issues rise again.
A leading factor in the creation of non-believers is the use of "fragile" documentation. Fragile, as opposed to resilient, documentation is a detailed description of a system that is manually maintained. By its nature, it is difficult to maintain and breaks the instant just one person neglects to update it once a system has changed. Smart people in the group quickly realize that the documentation is misleading, and then refuse to contribute - at all. The next section shows some of the key culprits in this type of situation.
The data graveyard
Microsoft Excel - Where data goes to die
Over the years I have seen countless Excel spreadsheets filled with information about systems. More often than not, these spreadsheets are de-normalized, poorly maintained, and overly burdened with the latest cool-looking, version-specific, features. I think of these documents as the gym shoes of the IT department - in them grows every bad habit of poor documentation maintenance.
My favorite* example is the ubiquitous IP address spreadsheet. In it we keep all the IP addresses of our production systems (you know, the ones that we keep in DNS) and our blocks of dynamic addresses (that are defined on the DHCP servers). So now we have addresses stored in Excel, DNS, DHCP, and on the systems themselves. Over a surprisingly short time, the odds of divergence of these sources approaches 1.
[* (When working in smaller subnets or organizations) I have always preferred to document all IP address usage in my DNS files. Comments can be used for reserved addresses (such as DHCP blocks) and individual systems. This allows for DNS lint programs to look for mistakes. The problem with this is many organizations use DNS appliances or GUIs that are not conducive to meta-data within the DNS databases; and more importantly because there are tools that exist specifically for IP address management (Google "IPAM" for some examples). What is relevant here is that whatever tool used, Excel represents another, easily de-synchronized version of the same data created in a tool not explicitly designed for database work, let alone this specific task.]
IP address requests at one particular IT organization routinely returned addresses that were in use. The spread sheet they used went hopelessly off the rails years ago and was completely out of sync with what was in DNS, DHCP, and (most importantly) the actual systems. Despite repeated errors, a devotion to the hallowed spread sheet persisted that can only be described as "religious". Naturally, this included no apologies for the inquisitions that followed the use of an invalid address.
[For the sake of argument; what is more valuable, all the time spent "maintaining" an out of synch spread sheet or writing a tool that pings / scans every address on a network and then records the last time each address responded? Neither is a solution, but one is likely to give me more reliable information than the other for about the same amount of effort.]
I am picking on Excel unfairly because it is the convenient whipping boy of this problem. It is really not about Excel, but the pointless exercise of maintaining fragile documentation. Whenever data is duplicated for anything other than reporting purposes the problem becomes one that requires absolute perfection from all those maintaining it. Once the first mistake finds it's way into the secondary copy it then becomes not only worthless but counter productive. It can never be trusted and becomes a time sink for its maintainers.
Job security
People feel safe living on knowledge islands of their own creation. These are the lessons on sharing we learned in kindergarden recklessly abandoned as an adult.
The goal of documentation is to capture info and share it to those who need it the most. This goal is often diametrically opposed to some personalities in the IT organization who believe that information is more valuable as a personal resource and therefore must be hoarded. Unfortunately this is a deep rooted philosophical / fear based approach that is extremely difficult to overcome.
It is unfortunate, but the blame for this problem falls back on the common culprit - management. People who have taken to information hoarding are by their very actions, adversaries of their co-workers. It will be exceptionally difficult for a peer to convince these people to loosen the reigns on the knowledge they hold. By carrot or by stick, management needs to convince information hoarders that the true path to job security lies in sharing and contributing to the group, rather than building information kingdoms.
If the promotion of the "happy workgroup" does not work, then management needs to realize the loss of value to the company when one employee refuses to contribute the value that was paid for in wages. Is the company paying it's employees to produce and sell wigits or play silly games of office politics?
I have heard of companies that refuse to let certain employees take simultaneous vacations or to fly on the same plane to some events. This is an admission that management has too much invested in a resource who is not showing an acceptable level of return.
[The counter argument is that sharing makes the employee more replaceable. I argue that this shield only lasts so long. Eventually the risk of the information island will be recognized and mitigated anyways. And if management is too dull to fix the problem, then they are probably equally dull to the potential loss, thus negating the value.]
It is a matter of taste
Each IT organization must make choices that work best for them. Some of these decisions cannot be mandated from outside but are specific to the cultural and technical makeup of that group.
Wiki, Word, or Web
Picking the right format
A trade off exists between reader value and contributor value. The group leader must choose a format that is most conducive for the information to be documented and the personalities who will be contributing. The question becomes: should you maximize the accessibility of the contributor making it easier for everyone to contribute against the ability for anyone to access.
The false trichotomy of word, wiki, and web is not meant to be exhaustive or that each is mutually exclusive, but a contrast of the more popular choices. Furthermore, this section tends to blur the difference between content format and the mechanism for storage, security, and presentation. The difference between format and management is touched on multiple times throughout this section.
| Description | Pros | Cons | |||||||||||||||||
| Word | Representative of any application that captures data in a format that requires a distinct, often version specific, application to access. The key defining criteria is 1) feature rich and 2) (by default) accessible only in the proprietary format. Excel and Visio are prime examples of this. Typically these apps can export / save as HTML but not as a native format. "Word" in some cases also implies a Windows SMB share. |
|
|
||||||||||||||||
| Web | An open standards free form system that most approaches custom documentation. "Web" specifically suggests HTML documents delivered over the HTTP(S) protocol. HTML may also include some of the "extensions" such as CSS or even scripting languages. This format has some commonality with "help" systems (such as the man pages). |
|
|
||||||||||||||||
| Wiki | Denoted by managed access to read and to write the data. Native format is in this case specific to the tool. A true wiki is usually a HTML subset, but may be expanded (in some contexts) to include tools like SharePoint and other content management environments. |
|
|
It is impossible for this article to fit the right tool to every reader, but I can make some general recommendations that may help in choosing what is best for your specific needs.
| • | Don't be a file format enforcer. Always use down-level and/or common file formats. When using MS Word or equivalents, don't automatically save to the latest version, you may be locking someone out. When using non-standard apps (like Visio), be sure to save to PDF or even a graphic format that can be viewed in all browsers. (Interesting note: While validating some of my comments on Microsoft SharePoint I was required to update Microsoft SilverLight to view the relevant pages at Microsoft.com.) |
| • | Use a format that will best suit your group. HTML (Web) documentation has a tendency to exclude people unfamiliar with HTML from the documentation process. Using (Windows) desktop oriented content management systems may become a frustrating bar of entry for people who work primarily in Unix or OSX. Being more inclusive potentially comes at the expense of the rich content of the proprietary formats or the flexible model of the (pure) web interface. |
| • | Carefully mix content when using Wiki. Allowing Wiki users to drop in rich content is nice in that it allows for representation of information in ways that the Wiki will not naturally support (ie: complex tables). The downside is that it is subject to abuse by people who put all data in a MS Word file, and then insert as a BLOB into the Wiki. The Wiki is at risk of simply becoming a glorified index of rich documents that it may not be able to index (for search). |
| • | Use bridge environments. The documentation format should be close to the system documented. (This is different than where to store the documentation.) The format and sharing method chosen should be friendly to the documented system. For example, a Unix shop that primarily manages systems via Unix workstations should not be expected to work exclusively from a Windows share in MS Office file formats. In this example, in the very least, the documentation directory should also be shared out via NFS. This would allow for natively formatted examples such as config files or scripts to be moved to/from the documentation store without introducing d.o.c.u.m.e.n.t. .e.n.c.o.d.i.n.g.,. . character—encoding–issues or EOL^M problems.^M |
| • | Mix it up. You can host MS Word docs on a web server, HTML files on a file server, or have a Wiki page link to external content. Use of one does not exclude the other, and format does not dictate sharing method. (Except for Wiki, the relationships between the two are rather weak.) That said, you should not allow the content to span too far and wide because then it becomes difficult to maintain or snap a copy for DR purposes. |
| • | Search is the lazy man's index. Manually maintaining links between documents or an index of contents can be rather time consuming. The ability to effectively search for all relative content is a powerful tool that should be exploited. A search tool needs to be capable of handling the file formats you have chosen and can span the locations where you store your docs. The glories of search aside, it is important that it not be used at the expense of a good manual index of system content and site navigation tools. |
| • | A Wiki by a different name. A ticketing system is a great resource for finding previous solutions or researching changes that lead to an outage. This type of system is a powerful tool to integrate with the more static documentation. |
Physical & Logical Considerations
It dosen't take a genius to see the problems with keeping your single copy of the detailed restore process on the fileserver that you may need to restore. This is intended as a humorous statement of the obvious, but unfortunately, it is a fresh concept to some. My preferred method is to make the documentation archivable so that it can be burned to hard media like a CD / DVD and then accessible on a company standard laptop that is likely to be used in an extreme DR situation. (Note: This is where Wiki and the specialized formats mentioned in the previous section begin to fail.) This is particularly useful for DR plans. Note, this can be problematic if security data is stored in the documentation. Secured / encrypted documents or portable password safes (self-encrypting miniature databases) may be a solution to this problem.
It may be beneficial to make the documentation store modular so that it can integrate with other IT departments or even non-IT groups for a comprehensive company-wide DR or compliance effort. Once again, it may be necessary to make some areas more restricted than others. When systems documentation is given to wider audiences, someone should be tasked with determining what is for public consumption and what is not.
A few recommended solutions
Here is a list of some safe bets for resolving documentation problems.
Like a carton of milk in the back of the fridge
Old documentation needs to expire - or come up for review.
Documentation should include meta-data that states when it expires, and who to contact when that date is reached. This insures that printed copies and older versions are not used beyond a reasonable date and acts as a simple versioning system.
There is a meta-data footer in the examples section below
Be careful to not use unrealistically short or long expiration dates. Short dates makes every document a maintenance nightmare. Long dates can lead to misleading and counter-productive documents. A standard date (timeframe) is OK, but each document / subject is different, so different time periods for different subject material should be allowed.
Not just how, but why
Stating how something is done is the obvious task of documentation; some people will want to know why it was done.
Operational people may simply be looking for steps to a process, while higher administrative and engineering types will want to know why a choice was made. Both groups should be addressed when explaining a process or a system.
The why of a process, system, or design decision provides some emphasis as well as direction. Future iterations of this project need to avoid pitfalls that held up the original design - and saving on redundant time consuming efforts is a fundamental tenet of the documentation effort. When an odd decision was made, future admins will want to correct what they believe to be a mistake with solutions that you have already shown not to work. Share the background, the why, of these decisions so that future changes can build on the knowledge that you achieved.
• Incomplete sentence of worthless info
Some file formats are simply unsuitable for documentation purposes.
It seems overkill to mention, but I bring it up because some people insist on using tools like Microsoft PowerPoint to relate data to readers - rather than ADD listeners at a presentation on the importance of cross paradigm synergies of multi-lingual bullet point representations in new media presentations. It is an obscure format that means the reader will need to launch a special application just to read a document full of bullet points and sentence fragments that really don't help in relating much beyond the concept called "frustration".
Take a picture, your keyboard will last longer
Documentation of physical objects can be easily documented by simply taking a photo.
One of the most popular memory games in the data center is which port on a multi-port NIC is the first. Effectively relating what port to use via text or by Visio diagram can be time expensive. Taking a picture and annotating the result is so much more accurate and faster than the alternatives.
One of the most effective documentation sets I have seen was created by an admin prior to a data center move. It was simply a flip-book of system names with annotated pictures of what connects to what. With documentation like that, we should have sent the technical guys home and let the movers finish the setup at the new location.
Document outside the box
Systems people like to document systems. App people like to document apps. Don't forget the relationship between the two.
Documenting outside of your domain insures that both the reader and the writer are more knowledgable of relationships to other systems and how each component fits in the overall environment. This is a variation on a theme expressed over and over in this document that a competent admin can quickly ascertain the configuration and key purpose of the system. The much more difficult part is what external systems connect to this, and what they are connecting for.
An application "environment" diagram is the most common example of this type of representation. Capturing data flow and dependencies between individual systems shows the reader valuable information that per-system documentation lacks.
Know what not to document
Automate tedious technical documentation.
High maintenance, fragile documentation can be automated via scripts and system tools. Conversely, stopping during each system change to revise a spreadsheet can be too much of a drag on efficiency.
One cool feature of automated (snapshot) documentation is that it can be used as a config time machine that allows you to pull a specific copy of the config from an archive of time stamped dumps. Using the previous metadata standard, the time created, what (script) created it, and when it expires (such as immediately*) can all be captured in the output.
[* Why "immediately"? Because a copy from the reporting tool is a secondary copy. The current config is always more accurate from the tool than a file. This is a generalization of these tools that can be adjusted for each specific case.]
Variations of this issue are discussed in both the fragile documentation and intent vs. actual sections below.
Writing letters to a future / previous you
Documentation needs to be written to someone who does not know what you currently know.
Every time I face this issue I remember one of many math classes where the teacher dismissed grand swaths of the solution as "trivial". This assumption about the knowledge of the audience is a reoccurring theme that I see every time information is relayed by someone who fundamentally understands it to someone who fundamentally does not. Once a technical hill has been climbed, we soon forget the difficulty of the journey.
When writing documentation I address a target audience as a technical neophyte, such as someone in HR, my grandma, or me in about three months. In short, I never make assumptions that they understand anything but the most simplistic administrations tasks - all other blanks must be filled in.
One may ask why I take such a hard line on this, particularly at the risk of writing overly verbose and remedial documentation. The answer is that we virtually always error in the other direction, and also because good writing is often seen as synonymous with speaking to a "higher level". Good writing, at least in this respect, is specifically about taking someone who does not understand what you are documenting and converting them into someone who does. Glossing over supporting technical details and introducing obscure technical terms without definitions does not help this cause.
Having a dialog with the reader
FAQ type documentation is extremely effective in getting through sticky points.
The FAQ give and take style allows the writer to specifically address items that were not so obvious in the rest of the documentation. Using a FAQ in addition to "regular" documentation allows normal specifics to be addressed as well as some of the obscure outliers.
Another aspect of having a dialog is use of more informal and potentially engaging verbiage in the document. As long as it does not cut into the technical content of the documentation, an informal approach makes for a more readable document that keeps the reader interested - and not constantly thinking of when the pain of reading this documentation will end.
OOD - (Object Oriented Documentation)
Reuse saves time - particularly if what your are reusing was written by an effective communicator.
Linking to, or even importing other (ie: vendor) documentation is a quick way to provide a solid background on the item without re-inventing the wheel. Never feel the need to re-write existing technical documentation unless it is really broken and needs clarification.
Keep it approachable
Do not alienate those who wish to access or contribute to documentation.
Enforcement of rigid standards or difficult versioning tools can alienate contributors. Balance between approachable and standardized is key. It is in this argument that the Wiki becomes a predominant player. Once again, choosing a tool like this is something that I am unable to dictate from this paper, but I can warn about avoiding unnecessarily frustrating road-blocks in the documentation process.
I think the number one reason for using version control systems for administrative files and documentation is to keep certain groups from making changes. It is like bug spray for the IT department. To take the analogy a step further, one should avoid spraying into the eyes.
Eliminate fragile documentation
Highly synchronized system "report" documentation should be scripted or generated from a tool for that purpose.
As mentioned earlier, fragile documents are really problematic for the group documentation effort. I will not consume valuable Internet bandwidth to stress this point more, except to say that the focus for this kind of documentation should not be writing / maintaining it, but instead on automating reports on it.
One other consideration is to, once again, focus on intent and overall design. We all know how to find an IP address on an interface but, six months on we struggle to remember why we put an extra IP address on that interface.
Leverage locality documentation
Don't make users go to remote documentation systems.
Effective documentation is about convenience and speed. The idea is to improve efficiencies in the environment by not forcing future admins to go to the ends of the web to find out how something works. One method of providing this is to deploy man pages on your systems relative to the changes and additions you have made. By documenting a complex or infrequently run operation in a man page, operators can quickly access important warnings or information that will reduce errors during these operations.
Scripts should support both -h and --help options and preferably have good inline documentation and a meaningful header that includes usage, intent, version and author information. I tend to write chatty scripts that tell what is about to happen and the status of what just happened - this makes the script well documented to the user as well as the maintainer.
I have seen meta data snippets dropped in the root directory of systems leveraged successfully by admins at many shops. Capturing key data such as prod / dev / test, key apps, and relationships in a text file can make finding your "location" (such as "on a production box") much easier and less error prone.
Gold mining in the unstructured kruft
Lots of value lies in the flotsam and jetsam of project notes that accompany a project.
I prefer to keep copious notes in both paper and electronic forms. The best of these sources should be compiled into the systems documentation, but the stuff that never makes it still has value. Paper notes (a project notebook) can be photocopied or scanned for needy coworkers. Electronic notes (project directories) can be archived into a tar file and stored with the documentation. (A project directory may contain variations on a config file, vendor supplied examples, documentation and patches.)
After years of paper notes, I am "trying" to move to electronic notes with the idea that they can be archived into a project much easier. Pen and paper is simply too natural or just too convenient for some types of data.
Intended v.s. actual documentation
Some "fragile" documentation may not be fragile at all. It is the standard to which a system is compared.
I have already discussed the futility in meticulously maintained documents of easily derived values. The difference here is that we acknowledge this document, script, or template may deviate from the actual system. It can be an expression of original design or a standard we wish to adhere to.
Documents of this nature should be marked as such. Archival design documents that the system no longer adheres to should become part of a dialog of changes to the system. These documents should be marked "archive", "prototype", or something similar to denote how it may deviate from current configs.
Most likely these documents, scripts, or templates are expressions of a standard. Like the archival version, these should be denoted as not necessarily a representation of the system, but a representation of what the system should be. These "documents" are typically in the form of a check / finish script that checks for deviations from the expected standard.
Extreme documentation
Extreme programming has an ugly step child.
Extreme documentation is a borrowed phrase to make reading this lengthy mess more interesting. It does not need to bring with it all the discipline of extreme programming - it is really about peer review of documentation.
This can entail two people working collaboratively on the documentation, the non-technical member writing for the technical, or just the documentation owner giving it a pass before putting it in with the rest of the documentation. The point here is that most technical people are not adept technical writers but are well versed in the subject material. Both of these limitations can be an impediment to good documentation. Review of another team member can be a solid assist.
Documenting software
Unix admins do write software on occasion, and it needs to be documented as well.
While software documentation was declared out of bounds for this article, it would be short sighted to ignore the volumes of scripts and code that systems people generate. When deploying internally written software, it is important to take the same care to capture the how's and why's that I have discussed with systems.
Scripts should have at a minimum:
| • | support for a help switch (option)* |
| • | a well written header that includes purpose, author, and version info |
| • | and inline comments. |
[* My preference is to "trigger lock" scripts that may be destructive. By default they should show help / usage info (and exit), and only do the intended change if a specific flag is passed as an option. This is because the standard destructive Unix utilities are well known, while the knowledge of the destructiveness of in-house utilities may not have been as widely disseminated.]
Internally written binaries are more rare, but have all the documentation needs of any other Unix utility - including a man page, proper source documentation, and versioning.
Some Examples
Examples are broken out because they may encompass more than one concept / recommendation.
"FAQ / discussion - Why" documentation:
The idea of this kind of documentation is to have a dialog with the reader to explain some of the more obvious issues that are bound to come up. This method has several benefits:
| 1) | it narrows in on key points that the reader will be interested in / author wishes to convey, |
| 2) | it is a convenient place to put items that are clearly relevant but often missed by the regular documentation, and |
| 3) | if a decision cannot be sufficiently argued then it is probably not a good idea to be implemented in the first place. |
This example addresses why the persons implementing a project (the subject of the documentation) chose to deploy "foo" instead of "bar". This documentation addresses why the decision was made, future direction, and mitigating factors of the decision in a few short sentences.
Why does the installation use foo over the more standardized bar?
Naturally we prefer to use the more standardized bar. Unfortunately bar was not version compatible with the baz we were required to run.
Yes, but now you have created a foo-compatibility legacy in the project.
No. foo compatibility will not be honored going forward. Do not rely upon the foo interface in scripts or tools.
To negate some of the uglier consequences of deploying foo, we deployed foo in bar compatibility mode. The idea is that when a copy of bar compatible with baz ships, we can then replace foo with the more standardized bar.
Meta-data Footer
Each document should have a minimal meta-data footer that includes the following information:
| • | Author / Maintainer with contact info |
| • | Expiration date and notice |
| • | Version information |
| • | Optional target audience |
This information can be placed as a footer on each page (MS Word / PDF documents) or at the footer of the entire document.
About this document
Author: John Doe <jdoe@gmail.com>
Version: 1.0 (June 18, 2010)
Expires: June 18, 2011
Contact the author / maintainer for an updated version of this document if your copy has expired. If the author / maintainer is unavailable, contact the IT department manager for a source of an updated copy.
Useful graphics
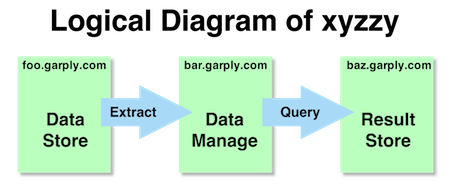
The following is an example of a logical diagram of the relationship between three systems. This image is successful in that it relates the purpose, relationship, and linkage of three different systems without being too verbose or too fragile (by including too detailed / specific) information such as IP addresses or the system type.
Other uses of graphics that are frequently used are screenshots. Screen / process captures provide info that the reader can visually relate to that is significantly easier than explaining the process through text. Excessive screen captures can swell the size and detract from the document flow, but the ability to quickly describe a process with such accuracy is of great value. The following is an example of an annotated screen shot that would probably be accompanied by brief text to explain the annotations (here in a high contrast red).
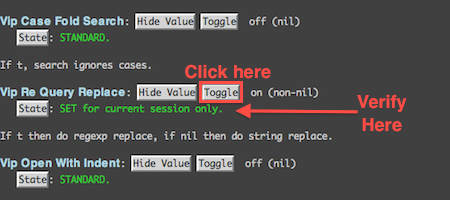
Giving background
Generally, the person implementing and documenting the project has a more solid understanding of the concepts than the reader. It is important that the author of the documentation not make assumptions about what the reader knows on the subject.
In the following example, the xyzzy process is explained both on an operational level as well as a procedural level. Additional note is given for using a precise time zone for a process that potentially crosses more than one time zone. Finally, the description includes both a break down of the steps (with sub-descriptions) along with a "more detail" link that takes the reader to a even deeper description of the procedure.
Note: If the "more detail" link goes off site, then this could be an issue for a DR project's documentation (that may need to be self-contained) and must also be checked as part of the documentation review.
Nightly xyzzy transfers
The xyzzy process runs as a nightly batch process. It is started automatically from the corge scheduler. It must be completed by 5 AM EST.
The nightly batch process is part of a standardized xyzzy transfer (hence the name of the process). It includes the following steps:
Additional information on standard xyzzy transfers can be found here.
Endnote
I have tried to utilize my own recommendations even in this document. With that in mind I will share my original intent of limiting this to three pages (with the idea that I would slip to four). The document now prints at 10 pages. So much for brevity.
By: William Favorite <wfavorite@tablespace.net>
Version: 1.0.1
Date: 8/8/10