| Main Page -> errbr |
errbr
[Introduction] [What's New] [Description] [Usage Notes] [Download] [Commentary]
Introduction:
errbr is a curses based AIX error log browser. It is designed as a quick and easy to use alternative to errpt and / or the diag commands. It displays a list of error log entries that can be used to browse or search through the error log using familiar key sequences and "drill-in" on specific errors, then back to the browse list to move on to other errors.
What's New:
The latest version now includes a background / worker thread that looks for new updates to the error log. The threaded model means that new errors will be displayed / available in the errbr interface as they are posted to the system error log.
This allows errbr to be used as a monitoring tool that works like a "tail" on the event log while still allowing for drill-in view access to individual errors.
Description:
errbr accepts basic emacs and vi key bindings for navigation and search functionality. These include: up/down, page up/down, goto top/bottom of list, and search.
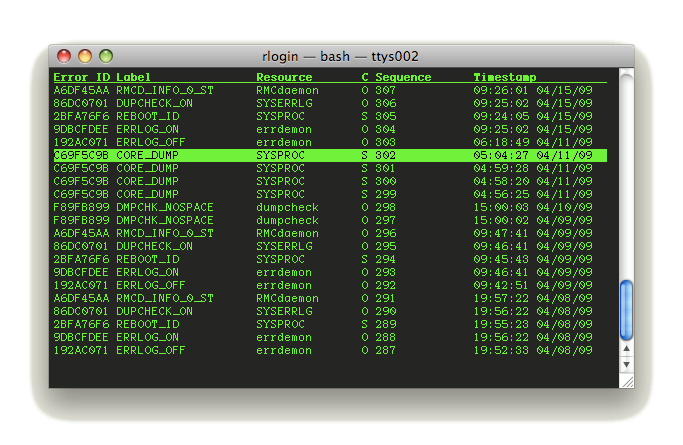
The following screenshot is from (a Macintosh Terminal.app session) to an AIX 5.3 system.
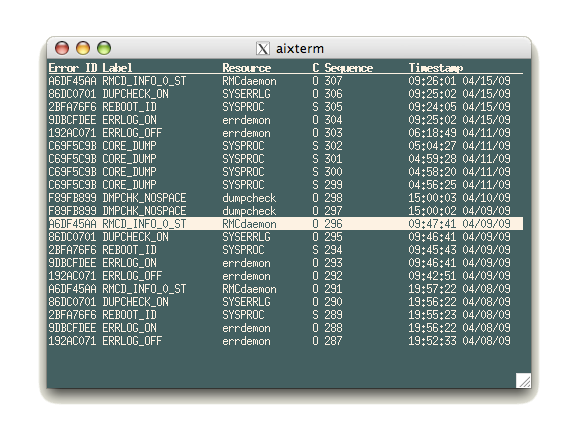
The following screenshot is from the same system but running over "aixterm"
Usage Notes:
errbr has worked in every validsee note terminal tested. Only in some limited cases that I tested did the terminal type cause problems, and this was typically resolvable via changes to terminal emulation settings.
[Note: "Valid" here means a terminal that will properly run curses apps. This qualification was added because of the OS-X version of xterm that would not properly run any curses app. (It lied about its own screen size.)]
The most notable problems are:
Additional usage notes can be found on the PDF version of the errbr man page.
The Distribution:
errbr53.2.0.0.0.bff (5.3 Package)
errbr61.2.0.0.0.bff (6.1 Package)
errbr-2_0_0.tar.gz (Source)
This code is released under a BSD-ish license. You can have it, use it, incorporate it, as long as the original author (William Favorite) is attributed in all redistributions and modified versions.
Code Commentary:
How to build:
Note: pre-built binary packages for 5.3 and 6.1 are available in the download section.
Build by uncompressing / untaring the package and running gmake. Make targets have been included for the binary, install, clean, and package build. It builds fine on 5.3 and 6.1. The makefile is (g)make specific and the compiler options are all gcc specific. There is no reason errbr could not be compiled using VAC - I just tend to use gcc for simple system tools like this.
Why are there two versions?
The errlog_open() API is version specific. The LE_MAGIC define is used to tell the errlog_open() call what version we are on. So compiling on each system will provide a different version for this #define. I do not know of an actual difference in the returned results, the errbr (non-library) code is the same in both versions. The versions here are simply respecting the fact that the open call magic value compiles different on different versions of the OS. The 5.3 compiled versions have worked without issue on 6.1 systems.
How does it work?
errbr starts by reading a limited set of errors into a local linked list. This linked list is used to generate a browsable view in the curses window. Once the list is built, a background / worker thread is spawned to maintain that list. Common key-bindings are used to navigate a cursor through the curses-based browse list. When a user chooses to view an error log entry, errpt is used to generate a error log reportsee note that errbr displays on the same screen.
[Note: See "Why use errpt?" for commentary.]Why pthreads?
It is true that errbr could process error updates during the normal breaks in the curses "event loop". It is also true that it could do it with sufficient speed that the user would never notice (even on the crappiest of systems). I did it because it seemed like the most "proper" method for updating the local (cached) copy of events. That, and I wanted to write some more pthreads code. I offer no other explanations.
Why curses?
I am no fan of curses programming - but it beats spawning an X or Java application to do something that should "just work" in a console (terminal) window. Curses is the only practical way to browse a list in the manner that errbr does from a terminal.
Why use errpt?
The error log structure as returned from the AIX error log API only contains half the story. It contains the raw (encoded) data from the error event, but not how to decode it. The error log template library contains the decoding information for errpt to decode the raw data and present in a meaningful format.
Even though the API is public, read (as in "decode") access to the template library is not. Note that you can write to the template library when you create your own event types - but this is just telling errpt (and only errpt) how to decode your newly added error entry.
A(n informal) request to have access to the error template library (via either an API or just a description of how to decode it) was made to the kind people of IBM Austin, but was denied. The only method to continue development of errbr, without costly attempts to decode the template library, was to just leverage errpt. As painful as this was, it was clearly the most cost-effective solution to the problem.
Handling Deleted Items
To properly sense, and respond in the user interface, when an error has been deleted from the event log it would be necessary to constantly query all events that are in the errbr browse list and then update the list. This is necessary because any event(s) can be removed from the log (not just the oldest).
The two (practical) methods I see are to only check when a new event has been added, or when there is a "cursor over" event. The first will only check when the event log has been updated with a new event. When a new event is added, then all existing events are checked to see that they are still maintained by the system. The second method would only check when the event is visible in the browse list (or under the current cursor / marker). If a missing (deleted) event is found, then a full scan could be completed.
The current (implemented) method is to only check when events are added. So when a new event is added, errbr will check its list against what is currently in the error log. If an error was deleted, then the sequence number (but not the event entry itself) will be removed from the display. This method is convenient in that if an error was deleted (possibly by another user or automated process) while errbr was running, and was not recognized by errbr, then the view screen will simply denote that the error does not exist. Meaning, it is handled about as gracefully as possible.
(Potential) Future Changes
The ability to save an error event to a (text) file would be a nice feature. I have not established a meaningful need for it at this time. If an actual need or just spare time to implement it arises, I may put it in the app.
Handling deleted items in the list remains a point of contention. The current solution works but is subject to modification in the future.
The thought of color-coding events has crossed my mind, but the most likely approach will be to filter on load (via a command line option) or filter from within the browse list. The most likely near-term solution is to filter on load.
Why write this at all?
AIX administrators have been dealing with this parse-the-error-log "limitation" for years. Why implement a solution to something that is clearly not a problem?
I thought that remembering obscure errpt options and calling it multiple times to walk through the error log was not very intuitive. I think that errbr is one case where AIX can be improved on.
That said, I am still soliciting comments on the value of the tool and ways in which it might be improved. All suggestions, comments, and critique is gratefully accepted.